はじめに
音声認識技術は、スマートフォンの音声アシスタントや翻訳アプリなどを通して広く利用されている。近年の音声認識では深層学習を用いたConformerやContextNetなどのモデルが精度を大きく改善している。しかし、音声認識の精度は音声認識を行うモデルに言語モデルを統合することで改善することができることが知られている。言語モデルとは、ある時刻\(t\)の情報をもとに時刻\(t+1\)の出力を予測するモデルである。今回は、音声認識モデルの言語モデルの統合方法について説明する。
言語モデルの統合方法
音声認識において、言語モデルの統合方法はshallow fusion, deep fusion, cold fusion, component fusionの4つがある。それぞれの統合方法の特徴を以下に示す。COMPONENT FUSION: LEARNING REPLACEABLE LANGUAGE MODEL COMPONENT FOR END-TO-END SPEECH RECOGNITION SYSTEMに違いがわかりやすく掲載されていたので図はそこから引用する。
まず、言語モデルがない音声認識モデルの図を示す。
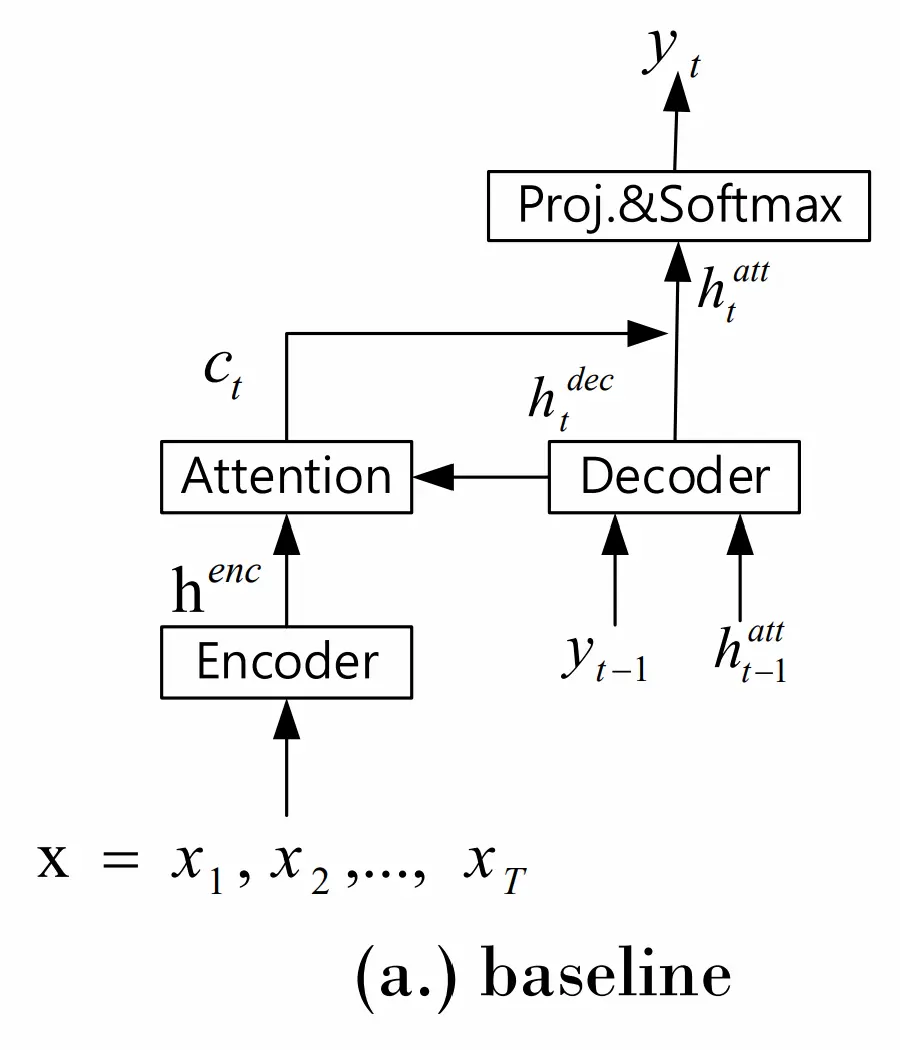 ここに言語モデルを足していくことになる。
ここに言語モデルを足していくことになる。
Shallow fusion
shallow fusionは最も多くのモデルに利用されているメジャーな方法である。
モデルの図を示す。
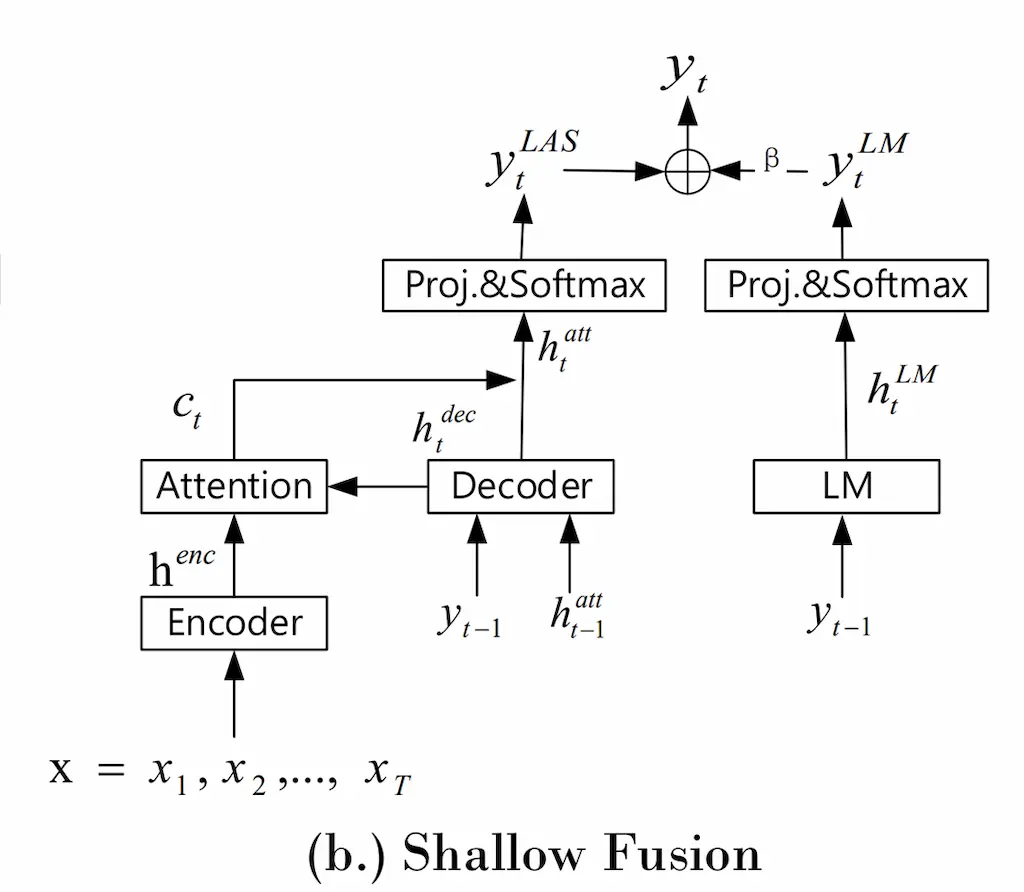 音声認識モデル部分には手を加えることなく、言語モデルを統合している。それぞれの出力を行った後言語モデルからの出力を\(\beta\)倍して足している。
式は以下のようになる。
音声認識モデル部分には手を加えることなく、言語モデルを統合している。それぞれの出力を行った後言語モデルからの出力を\(\beta\)倍して足している。
式は以下のようになる。
\[y_{t} = arg max(\log{(y_{t}^{LAS})} + \beta log{(y_{t}^{LM})})\]
Deep fusion
Deep fustionは、言語モデルを内部の特徴量の段階で統合したモデルである。
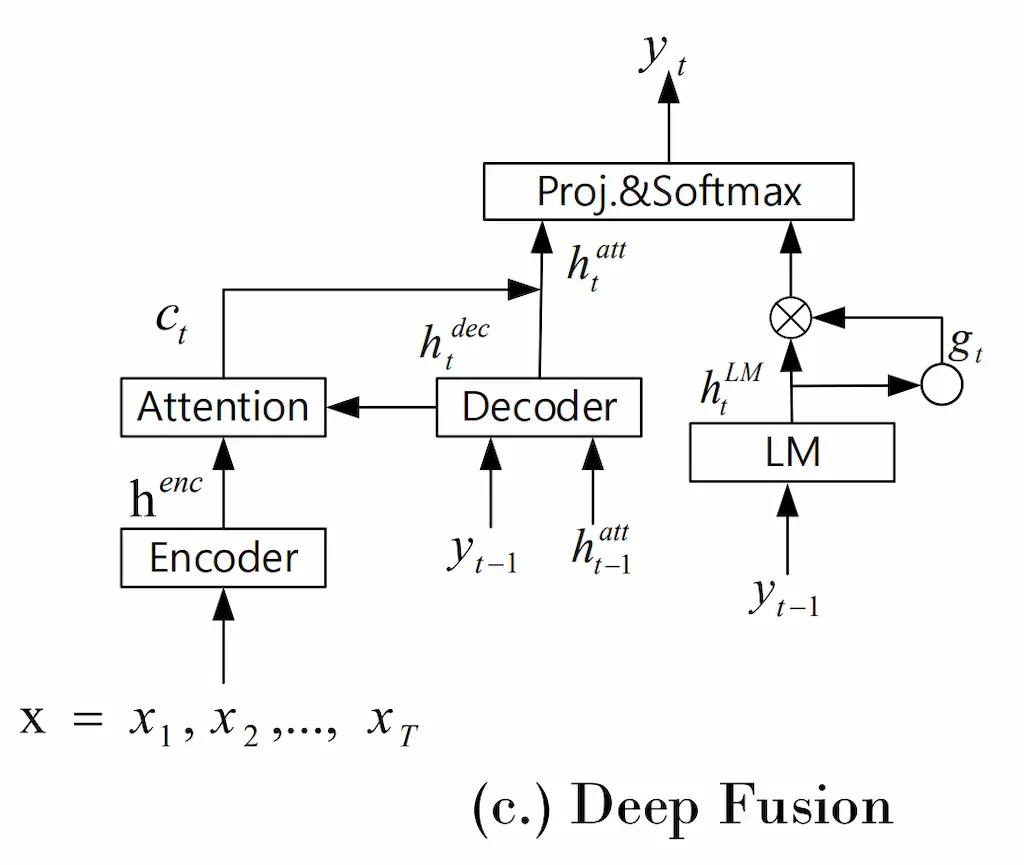
\[ \begin{aligned} g_t &= sigmoid(U_gs_t^{LM}+b) \\ \hat{h}_{t}^{att} &= [h_t^{att};g_ts_t^{LM}] \\ y_t &= softmax(W_o^’\hat{h}_t^{att}) \end{aligned} \]
ここで,\([x;y]\)は\(x\)と\(y\)をconcatしたものを表している。 \(g_t\)は\(U_g\)によって調整されるパラメータであり、言語モデルの出力\(s_t^{LM}\)の情報をそれぞれのパラメータについてどれだけ利用するのかを決めている。その後、ASRモデルからの出力とconcatして\(y_t\)を計算している。
Cold fusion
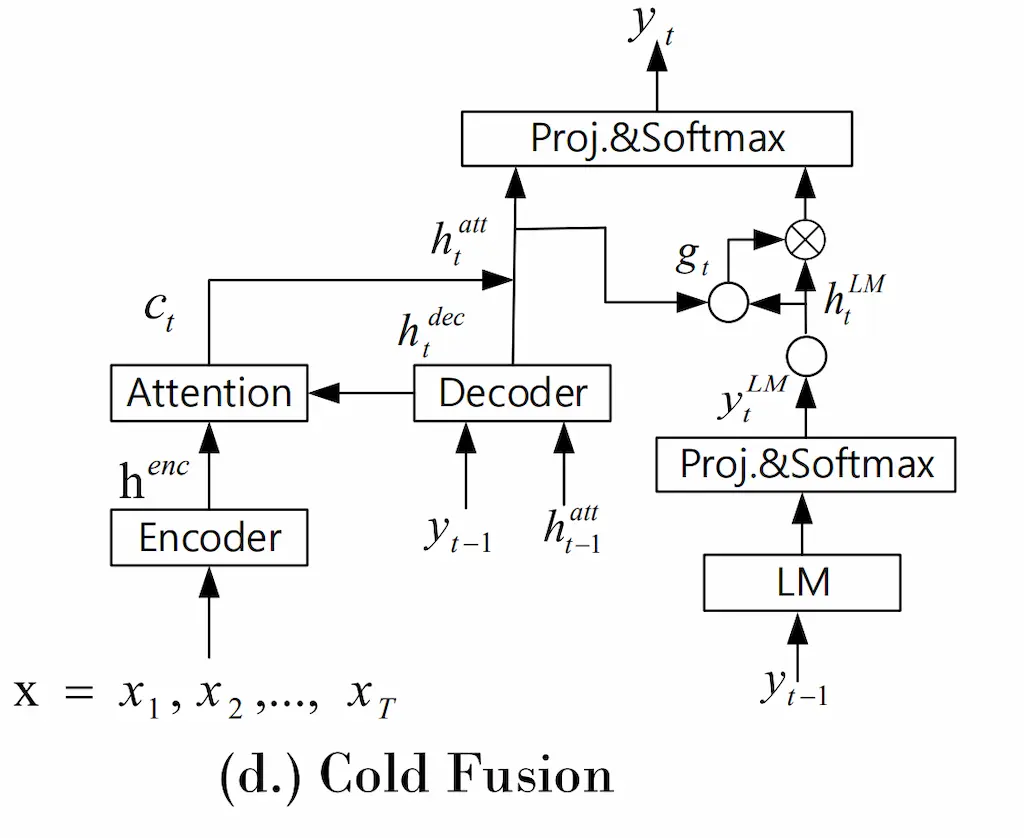
\[ \begin{aligned} h_t^{LM} &= DNN(l_t^{LM}) \\ g_t &= sigmoid(U_g[h_t^{LM};h_t^{att}]+b) \\ \hat{h}_t^{att} &= [h_t^{att};g_th_t^{LM}] \\ y_t &= softmax(W_o^’\hat{h}_t^{att}) \end{aligned} \]
cold fusion では、言語モデルを利用する際、言語モデルの特徴量からのみで\(g_t\)を計算していたが、deep fusionではASRモデルからの情報も利用して利用する言語モデルの特徴量を決定する。
component fusion
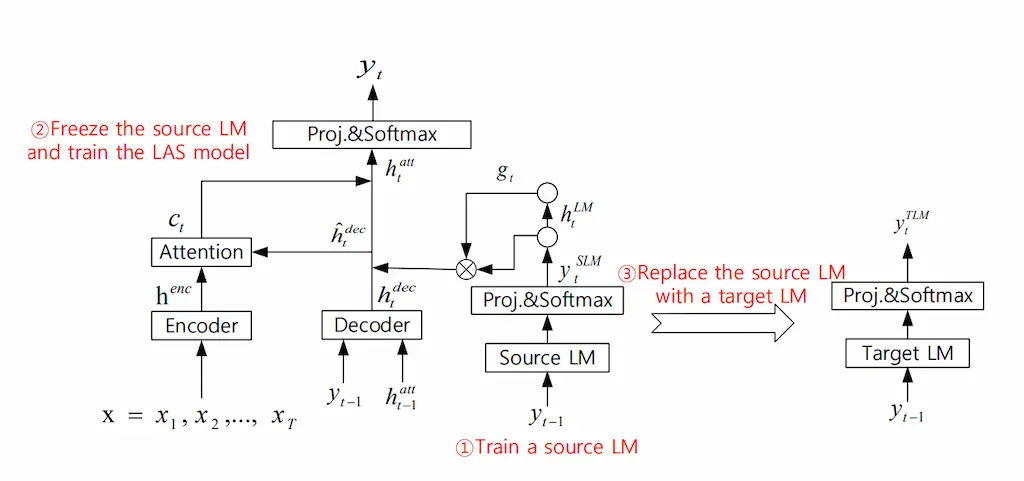
cold fustionをベースに言語モデルを切り離した方法である。まず初めに、言語モデルをASRモデルのラベルによって学習する。これによって高速で学習し、学習データのドメインにも対応できる。また、言語モデル自体を取り替えることもできる。また、このモデルでは言語モデルの特徴量を早期に結合しているため、よりASRモデルの浅い段階から学習に影響を与えるよう改良されている。
Reference
- Towards better decoding and language model integration in sequence to sequence models
- Cold Fusion: Training Seq2Seq Models Together with Language Models
- On using monolingual corpora in neural machine translation
- COMPONENT FUSION: LEARNING REPLACEABLE LANGUAGE MODEL COMPONENT FOR END-TO-END SPEECH RECOGNITION SYSTEM