HuBERT
発表学会と発表者
- Facebook AI
- IEEE/ACM Transactions on Audio, Speech, and Language Processing 29 (2021)
https://arxiv.org/pdf/2106.07447.pdf
HuBERT誕生の背景
深層学習を用いた音声認識では、Transformerの登場によって従来のLSTMなどのRNNベースの手法から精度がさらに向上した。しかし、この手法はラベル付きの学習データが大量に必要となる。これを回避するためにSelf-Supervised learningを活用しようという動きが見られるようになった。HuBERTは音声におけるBERTのような役割を果たすと考えている。
HuBERTの概要
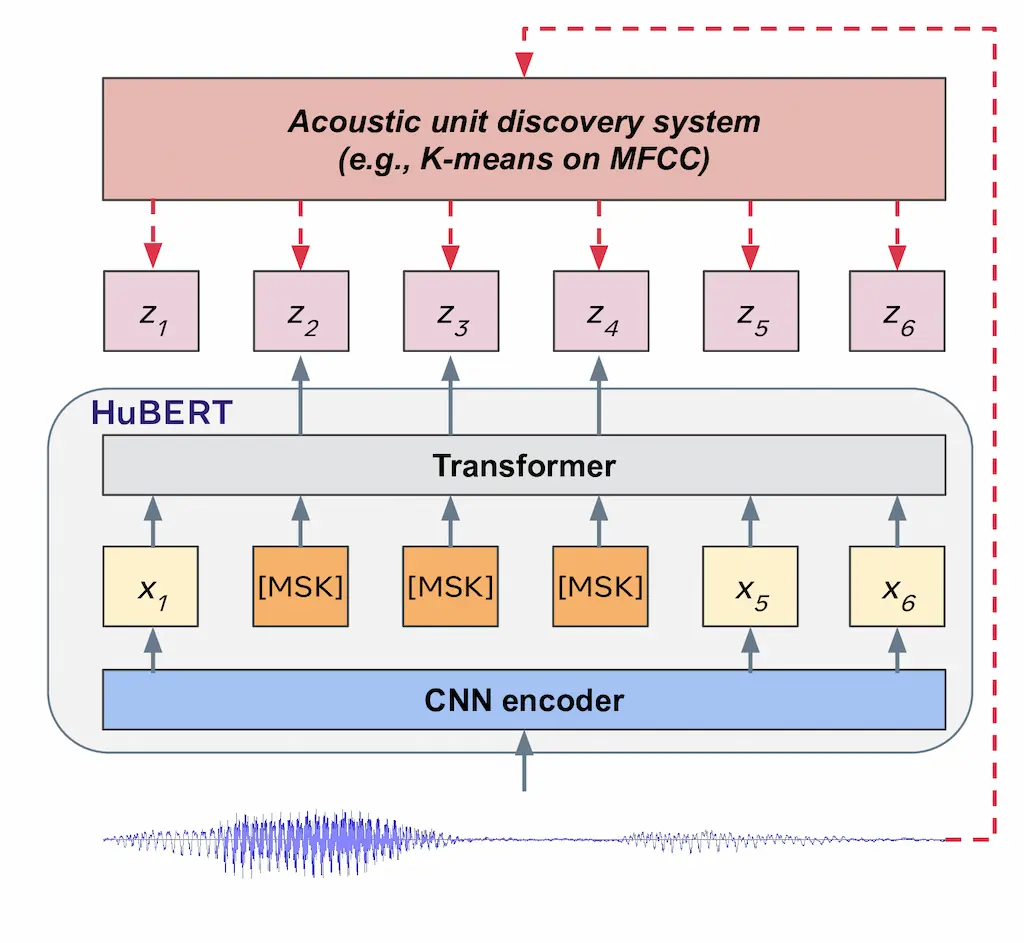 Hidden-UnitBERT(HuBERT)は、自己教師あり学習(Self-supervised learning)による音声の表現学習モデルである。自己教師あり学習とは、ラベルのついていないデータに対して、データからラベルを自動的に作成できるような汎用的なタスクによる学習を指す。また、自己教師あり学習のような、特定のタスクに依存せず汎用的な特徴表現を獲得する学習を総称して表現学習と呼ぶ。HuBERTは、クラスタリングにより音声データから疑似ラベルを作成し、音声データの一部をマスクしてその疑似ラベルを予測するMasked Language Model(MLM)による事前学習を行う。なお、疑似ラベルは学習中に更新され、特徴表現が徐々に改善される。音声データに対するMLMの学習を行うことで、HuBERTは音響モデルと言語モデルの両方を学習する。その後、音声認識などの目的のタスクによるFine-Tuningを行うことで、少量のラベル付きデータであっても高い性能を有することができる。
Hidden-UnitBERT(HuBERT)は、自己教師あり学習(Self-supervised learning)による音声の表現学習モデルである。自己教師あり学習とは、ラベルのついていないデータに対して、データからラベルを自動的に作成できるような汎用的なタスクによる学習を指す。また、自己教師あり学習のような、特定のタスクに依存せず汎用的な特徴表現を獲得する学習を総称して表現学習と呼ぶ。HuBERTは、クラスタリングにより音声データから疑似ラベルを作成し、音声データの一部をマスクしてその疑似ラベルを予測するMasked Language Model(MLM)による事前学習を行う。なお、疑似ラベルは学習中に更新され、特徴表現が徐々に改善される。音声データに対するMLMの学習を行うことで、HuBERTは音響モデルと言語モデルの両方を学習する。その後、音声認識などの目的のタスクによるFine-Tuningを行うことで、少量のラベル付きデータであっても高い性能を有することができる。
HuBERTのモデル構造
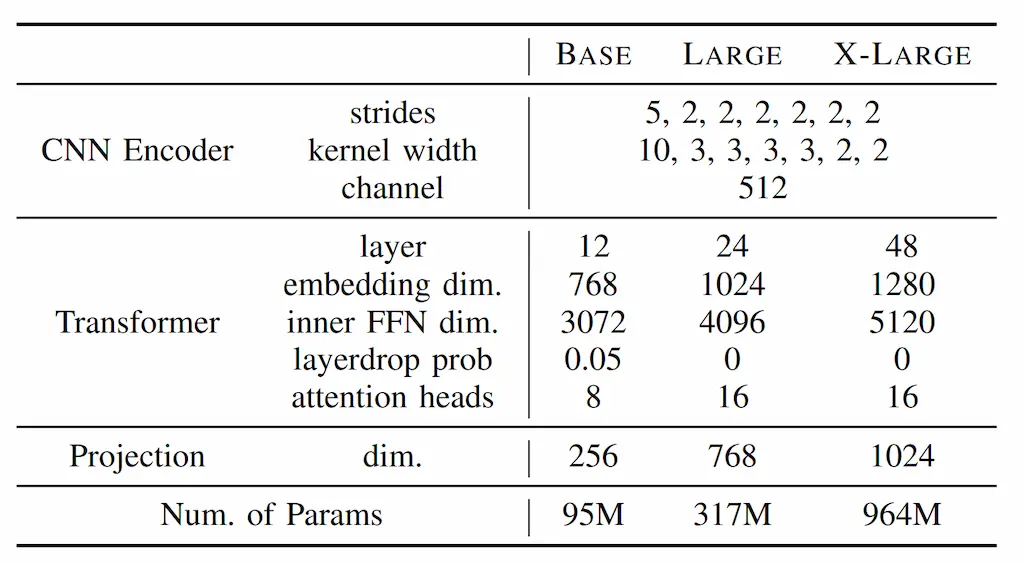
HuBERTのモデル構造はWav2vec2.0を基にしている。HuBERTのモデル構造を表に示す。HuBERTは、CNNEncoder、TransformerEncoder、ProjectionLayerから構成される。HuBERTは、MFCCなどの特徴量抽出を事前に行わず、代わりに一次元畳み込みからなるCNNEncoderによって生の音声から特徴量抽出を行う。その後、Transformerによってエンコードされ、全結合層からなるProjectionLayerに渡される。ProjectionLayerは、事前学習において疑似ラベルを予測するために用いられる層である。また、HuBERTはモデルの規模によってBASE、LARGE、X-LARGEの3つの構成が提案されている
クラスタリングによる疑似ラベルの作成
HuBERTは、DeepClusterより着想を得ており、k-meansなどのクラスタリングにより音声データから疑似ラベルを作成する。CNNEncoderによって特徴量抽出された音声特徴量\(X=[\bm{x}_1,\cdots,\bm{x}_T]\)に対して、フレーム単位の疑似ラベル\(Z=[z_1,\cdots,z_T]\)は、生の音声より特徴量抽出されたMFCCをクラスタリングすることで得られる。なお、\(z_t\in[C]\)は\(C\)クラスのカテゴリ変数であり、クラス数はクラスタリングを行うときのクラスタ数によって決定される。また、系列長\(T\)は、MFCCのフレーム化に合わせて、CNNEncoderのカーネルサイズやストライドによって調整されている
疑似ラベルの改良HuBERTは、後述するMasked Language Model(MLM)による学習中にクラスタリングを反復的に行うことで、疑似ラベルを改良する。学習前はMFCCに対してクラスタリングを行っていたが、学習中はモデル中間の出力に対して行う。クラスタリングと学習を交互に行うことで、モデルおよび疑似ラベルを段階的に改善する。ClusterEnsemblesHuBERTは、複数のクラスタリングによる疑似ラベルを用いたアンサンブル学習を行う。複数のクラスタリングは、異なるサイズのクラスタ数や異なる特徴量によるクラスタリングによって行われる。複数のクラスタリングを行うことで、異なるスケール(母音、子音、セノン)における疑似ラベルを作成することができる。以下、\(k\)個目のクラスタリングによる疑似ラベルを\(Z^{(k)}=[z^{(k)}_1,\cdots,z^{(k)}_T]:(z^{(k)}_t\in C^{(k)})\)とする。また、クラスタ\(c\)の重心ベクトルを\(\bm{e}_c\)とする。
MaskedLanguageModelによる事前学習
MLMは、系列データに対して一定の確率でマスクし、そのマスクされた内容を予測するタスクである。HuBERTのMLMでは、音声特徴量\(\bm{x_{1}},\cdots,\bm{x_{T}}\)の各フレームに対して、確率\(p\)で開始インデックスとして選択し、長さが\(l\)のマスクをかける。以下、マスクされるフレームの集合を\(M\subset[T]\)とし、\(X\)を\(M\)の範囲でマスクした系列を\(\tilde{X}=r(X,M)\)とする。なお、実験では、\(p=0.08、l=10\)が用いられている。MLMの損失\(Lm\)は交差エントロピーに基づいており、マスク部分を予測するHuBERTモデルfに対して以下の式で表される。\[L_m(f;X,{Z^{(k)}},M)=-\sum_{t\in M}\sum_{k}\log p^{(k)}_f(z^{(k)}_t|\tilde{X},t)\]
なお、\(p^{(k)}_f(c|\tilde{X},t)\)は、HuBERTモデル\(f\)に対して、マスクされた音声特徴系列\(\tilde{X}\)を入力としたときの時刻\(t\)における\(k\)個目の疑似ラベルのクラス\(c\)の予測確率を表す。マスクされた音声から事前に割り当てられたクラスタを予測するため、周囲のマスクされていない入力から高度な特徴表現を学習する必要がある。したがって、HuBERTはMLMによって、音声からより良い特徴量を抽出する音響モデルと系列の文脈を理解する言語モデルの両方が学習される
疑似ラベルの予測確率の算出疑似ラベルの予測確率\(p^{(k)}_f(c|\tilde{X},t)\)の算出方法について述べる。マスクされた音声特徴系列\(\tilde{X}\)に対してHuBERTのTransformerEncoderの出力を\([\bm{o}_1,\cdots,\bm{o}_T]\)、\(k\)個目のクラスタリングに対するProjectionLayerを\(A^{(k)}\)とすると、疑似ラベルの予測確率\(p^{(k)}_f(c|\tilde{X},t)\)は以下の式で表される。
\[p_{(c|\tilde{X},t)}^{(k)} = \frac{\exp(\text{sim}(A^{(k)}\bm{o_t},\bm{e_c}))/\tau}{\sum_{C^{(k)}}^{c^{\prime=1}} \exp(\text{sim}(A^{(k)}\bm{o}_t,\bm{e_c^\prime})/\tau)} \]
ここで、\(\text{sim}(\cdot,\cdot)\)はコサイン類似度を表し、\(\tau=0.1\)は温度パラメータである。式(4。2)にあるように、疑似ラベルの予測確率は、各クラスタの重心ベクトルとの類似度をsoftmax関数により正規化した値である。