はじめに
Lineには、トーク履歴をエクスポートする機能が付いています。これをPythonを使って解析し、合計メッセージ数、それぞれのメッセージ数、合計文字数、それぞれのメッセージ数、Line電話の時間の合計をそれぞれの月について算出する方法です。筆者は、電子機器の言語を英語に設定しているため、日本語を使用されている方は、履歴のファイル名や内容が日本語表記になっていることが予想されます。適宜読み替えてください。
Lineからトーク履歴をエクスポートする
これは、PCでもスマホでもできますが、PCとスマホでは、エクスポートされたトーク履歴のフォーマットが微妙に違うことやPCでは、エクスポートできるトーク履歴が会話全体の一部でしかないため、今回はスマホでエクスポートし、PCに送りました。
トーク履歴をCSVに変換する
エクスポートされたファイルは、[LINE] Chat with [friend name].txtとなっていました。フォーマットは以下のようでした。うーん、このフォーマットは使いにくい気が…
1~略~
22021/03/03 Wed
310:15 frinds account name 次の電話は明日の18時半がいいです。
411:37 my account name [Sticker]
5~略~
日時、タブ、アカウント名、タブ、メッセージとなっています。
Lineには様々な機能が付いています。テキストメッセージ、写真、動画、スタンプ、電話、アルバム、メッセージの取り消しなどのシステムメッセージ…。これらは履歴の中では、特定の形で表現されているので、それぞれの履歴がどの種類のメッセージであるかを正規表現を使って分け、csvに変換していきます。csvの形式は年,月,日,時,分,送信者,内容,flagとします。flagについては後述します。
履歴ファイルを読み込む
履歴ファイルを読み込みます。
1file_path = "[LINE] Chat with [freind name].txt"
2with open(file_path, 'r', encoding="utf-8") as f:
3 log_text = f.read()
正規表現を設定する
それぞれのメッセージ種別について正規表現を設定していきます。
1# 日時データ
2date_pattern = r"20\d{2}/\d{2}/\d{2} (Mon|Tue|Wed|Thu|Fri|Sat|Sun)"
3# テキストメッセージデータ
4message_pattern = r"\d{2}:\d{2}\t.*\t.*"
5# 写真のデータ
6photo_pattern = r"\d{2}:\d{2}\t.*\t\[Photo]"
7# スタンプのデータ
8sticker_pattern = r"\d{2}:\d{2}\t.*\t\[Sticker]"
9# ビデオデータ
10video_pattern = r"\d{2}:\d{2}\t.*\t\[Video]"
11# ファイルのデータ
12file_pattern = r"\d{2}:\d{2}\t.*\t\[File]"
13# アルバム作成、名前変更、削除のデータ
14album_build_pattern = r"\d{2}:\d{2}\t.*\t\[Albums].*"
15album_rename_pattern = r"\d{2}:\d{2}\t.* changed the name of the album.*"
16album_delete_pattern = r"\d{2}:\d{2}\t.* delete the album.*"
17# 電話のデータ関係
18missed_call_pattern = r"\d{2}:\d{2}\t.*\t☎ Missed call"
19canceled_call_pattern = r"\d{2}:\d{2}\t.*\t☎ Canceled call"
20no_answer_call_pattern = r"\d{2}:\d{2}\t.*\t☎ No answer"
21call_pattern = r"\d{2}:\d{2}\t.*\t☎ Call time (\d{1,2}:\d{2}|\d{1,2}:\d{2}:\d{2})"
22# システムのデータ、送信取り消し
23sys_unsent_pattern = r"\d{2}:\d{2}\t.* unsent a message."
データを正規表現に沿って解析する
re.match()で正規表現に当てはまっているかを確認し、当てはまっていたら、タブでデータを分割したのち、Data型にデータを格納し、リストlogに追加していきます。データ型のflagという変数はデータの種類を示しており、以下のように設定しています。
1# flag
2 # 0 : talk meassge
3 # 10 : call
4 # 11 : missed call
5 # 12 : canceled call
6 # 13 : no answer call
7 # 2 : photo
8 # 3 : video
9 # 4 : sticker
10 # 50 : system message unsent
11 # 60 : file
12 # 70 : create and add album
13 # 71 : changed the name of the album
14 # 72 : deleted the album
1class Data():
2 def __init__(self, year, month, day, hour, minute, person, payload, flag):
3 self.year = year
4 self.month = month
5 self.day = day
6 self.hour = hour
7 self.minute = minute
8 self.person = person
9 self.payload = payload
10 self.flag = flag
11
12date_ = datetime.datetime.now()
13logs = []
14
15# 履歴の最初の2行はエクスポートした時間と空白の行なのでとばし、3行目から解析する
16for i, log in enumerate(log_text.splitlines()[3:]):
17 #print(f"{log} : ", end='')
18 if log == '':
19 #print("no data")
20 continue
21 date_stamp = ""
22 if re.match(date_pattern, log):
23 #print("day data")
24 date_stamp = log.replace('/', ',').replace(' ', ',')[0:10]
25 date_ = datetime.datetime.strptime(date_stamp, '%Y,%m,%d')
26 elif re.match(photo_pattern, log):
27 #print("photo data")
28 splited_log = re.split('\t', log)
29 logs.append(Data(date_.year, date_.month, date_.day,
30 splited_log[0][0:2], splited_log[0][3:5], splited_log[1], "", 2))
31 elif re.match(video_pattern, log):
32 #print("Video data")
33 splited_log = re.split('\t', log)
34 logs.append(Data(date_.year, date_.month, date_.day,
35 splited_log[0][0:2], splited_log[0][3:5], splited_log[1], "", 3))
36 # ~略~
csvを保存する
以下のコードでcsvファイルを保存します。line.csvというファイルに保存されます。
1with open('line.csv', 'w', encoding="utf-8", newline="") as f:
2 for content in logs:
3 writer = csv.writer(f)
4 writer.writerow([str(content.year), str(content.month), str(content.day), str(content.hour),str(content.minute), str(content.person), str(content.payload), str(content.flag)])
トーク履歴をCSVに変換するコードの全体
ここまでのコードの全体です
1# -*- coding: utf-8 -*-
2
3import re
4import csv
5import datetime
6import os
7import sys
8
9
10class Data():
11 # flag
12 # 0 : talk meassge
13 # 10 : call
14 # 11 : missed call
15 # 12 : canceled call
16 # 13 : no answer call
17 # 2 : photo
18 # 3 : video
19 # 4 : sticker
20 # 50 : system message unsent
21 # 60 : file
22 # 70 : create and add album
23 # 71 : changed the name of the album
24 # 72 : deleted the album
25 def __init__(self, year, month, day, hour, minute, person, payload, flag):
26 self.year = year
27 self.month = month
28 self.day = day
29 self.hour = hour
30 self.minute = minute
31 self.person = person
32 self.payload = payload
33 self.flag = flag
34
35
36# disable #print
37# sys.stdout = open(os.devnull, 'w', encoding="utf-8")
38
39file_path = "[LINE] Chat with friend.txt"
40
41date_ = datetime.datetime.now()
42logs = []
43
44# open file and load data
45with open(file_path, 'r', encoding="utf-8") as f:
46 log_text = f.read()
47
48date_pattern = r"20\d{2}/\d{2}/\d{2} (Mon|Tue|Wed|Thu|Fri|Sat|Sun)"
49message_pattern = r"\d{2}:\d{2}\t.*\t.*"
50photo_pattern = r"\d{2}:\d{2}\t.*\t\[Photo]"
51sticker_pattern = r"\d{2}:\d{2}\t.*\t\[Sticker]"
52video_pattern = r"\d{2}:\d{2}\t.*\t\[Video]"
53file_pattern = r"\d{2}:\d{2}\t.*\t\[File]"
54album_build_pattern = r"\d{2}:\d{2}\t.*\t\[Albums].*"
55album_rename_pattern = r"\d{2}:\d{2}\t.* changed the name of the album.*"
56album_delete_pattern = r"\d{2}:\d{2}\t.* delete the album.*"
57missed_call_pattern = r"\d{2}:\d{2}\t.*\t☎ Missed call"
58canceled_call_pattern = r"\d{2}:\d{2}\t.*\t☎ Canceled call"
59no_answer_call_pattern = r"\d{2}:\d{2}\t.*\t☎ No answer"
60call_pattern = r"\d{2}:\d{2}\t.*\t☎ Call time (\d{1,2}:\d{2}|\d{1,2}:\d{2}:\d{2})"
61sys_unsent_pattern = r"\d{2}:\d{2}\t.* unsent a message."
62
63for i, log in enumerate(log_text.splitlines()[3:]):
64 #print(f"{log} : ", end='')
65 if log == '':
66 #print("no data")
67 continue
68 date_stamp = ""
69 if re.match(date_pattern, log):
70 #print("day data")
71 date_stamp = log.replace('/', ',').replace(' ', ',')[0:10]
72 date_ = datetime.datetime.strptime(date_stamp, '%Y,%m,%d')
73 elif re.match(photo_pattern, log):
74 #print("photo data")
75 splited_log = re.split('\t', log)
76 logs.append(Data(date_.year, date_.month, date_.day,
77 splited_log[0][0:2], splited_log[0][3:5], splited_log[1], "", 2))
78 elif re.match(video_pattern, log):
79 #print("Video data")
80 splited_log = re.split('\t', log)
81 logs.append(Data(date_.year, date_.month, date_.day,
82 splited_log[0][0:2], splited_log[0][3:5], splited_log[1], "", 3))
83 elif re.match(sticker_pattern, log):
84 #print("Sticker data")
85 splited_log = re.split('\t', log)
86 logs.append(Data(date_.year, date_.month, date_.day,
87 splited_log[0][0:2], splited_log[0][3:5], splited_log[1], "", 4))
88 elif re.match(call_pattern, log):
89 #print("call data")
90 splited_log = re.split('\t', log)
91 time_data = splited_log[2][12:]
92 time_data = re.split(':', time_data)
93 time_length = 0
94 for i in range(len(time_data)):
95 time_length += int(time_data[len(time_data) - i - 1]) * (60 ** i)
96 # print(time_length)
97 logs.append(Data(date_.year, date_.month, date_.day,
98 splited_log[0][0:2], splited_log[0][3:5], splited_log[1], time_length, 10))
99 elif re.match(missed_call_pattern, log):
100 #print("Missed call data")
101 splited_log = re.split('\t', log)
102 logs.append(Data(date_.year, date_.month, date_.day,
103 splited_log[0][0:2], splited_log[0][3:5], splited_log[1], "", 11))
104 elif re.match(canceled_call_pattern, log):
105 #print("Canceled call data")
106 splited_log = re.split('\t', log)
107 logs.append(Data(date_.year, date_.month, date_.day,
108 splited_log[0][0:2], splited_log[0][3:5], splited_log[1], "", 12))
109 elif re.match(no_answer_call_pattern, log):
110 #print("no answer call data")
111 splited_log = re.split('\t', log)
112 logs.append(Data(date_.year, date_.month, date_.day,
113 splited_log[0][0:2], splited_log[0][3:5], splited_log[1], "", 13))
114 elif re.match(sys_unsent_pattern, log):
115 #print("sys unsent data")
116 splited_log = re.split('\t', log)
117 logs.append(Data(date_.year, date_.month, date_.day,
118 splited_log[0][0:2], splited_log[0][3:5], "", "", 50))
119 elif re.match(file_pattern, log):
120 #print("file data")
121 splited_log = re.split('\t', log)
122 logs.append(Data(date_.year, date_.month, date_.day,
123 splited_log[0][0:2], splited_log[0][3:5], "", "", 60))
124 elif re.match(album_build_pattern, log):
125 #print("create album data")
126 splited_log = re.split('\t', log)
127 logs.append(Data(date_.year, date_.month, date_.day,
128 splited_log[0][0:2], splited_log[0][3:5], "", "", 70))
129 elif re.match(album_rename_pattern, log):
130 #print("rename album data")
131 splited_log = re.split('\t', log)
132 logs.append(Data(date_.year, date_.month, date_.day,
133 splited_log[0][0:2], splited_log[0][3:5], "", "",71))
134 elif re.match(album_delete_pattern, log):
135 #print("delete album data")
136 splited_log = re.split('\t', log)
137 logs.append(Data(date_.year, date_.month, date_.day,
138 splited_log[0][0:2], splited_log[0][3:5], "", "", 72))
139 elif re.match(message_pattern, log):
140 #print("message data")
141 splited_log = re.split('\t', log)
142 logs.append(Data(date_.year, date_.month, date_.day,
143 splited_log[0][0:2], splited_log[0][3:5], splited_log[1], splited_log[2], 0))
144 elif (len(re.split('\t', log)) == 1):
145 splited_log = re.split('\t', log)
146 #print("returned data")
147 logs[-1].payload += log
148 else:
149 pass
150 #print("\nNo classified data\n")
151
152with open('line.csv', 'w', encoding="utf-8", newline="") as f:
153 for content in logs:
154 writer = csv.writer(f)
155 writer.writerow([str(content.year), str(content.month), str(content.day), str(content.hour),str(content.minute), str(content.person), str(content.payload), str(content.flag)])
156
157print("Success🎉")
CSVを解析するし、グラフを生成する
CSVの解析にはpandas、グラフの生成にはmatplotlibをpandasのラッパーを通して利用してます。ラッパーなので生成されるグラフはmatplotlibそのものです。
CSVを読み込む
CSVをpandasを利用して読み込みます
1file_path = "line.csv"
2df = pd.read_csv(file_path, names=('year', 'month', 'day',
3 'hour', 'minute', 'person', 'payloads', 'flag'), encoding="UTF-8")
全体の月別メッセージ数
pandasのgroupby機能によって月ごとのメッセージ数を数えます。これをグラフにします。ほかのデータを解析する場合も基本は同様です。これを少し変えることで、曜日別や時間別なども簡単に作ることができそうです。
1month_message = df[["year", "month", "flag"]
2 ].groupby(['year', 'month']).count()
3
4month_message.plot(y='flag', kind='bar', label="count", figsize=figsize)
5plt.ylabel("message count")
6plt.legend()
7plt.ylim(0,)
8plt.title('message')
9plt.savefig('message_count.png')

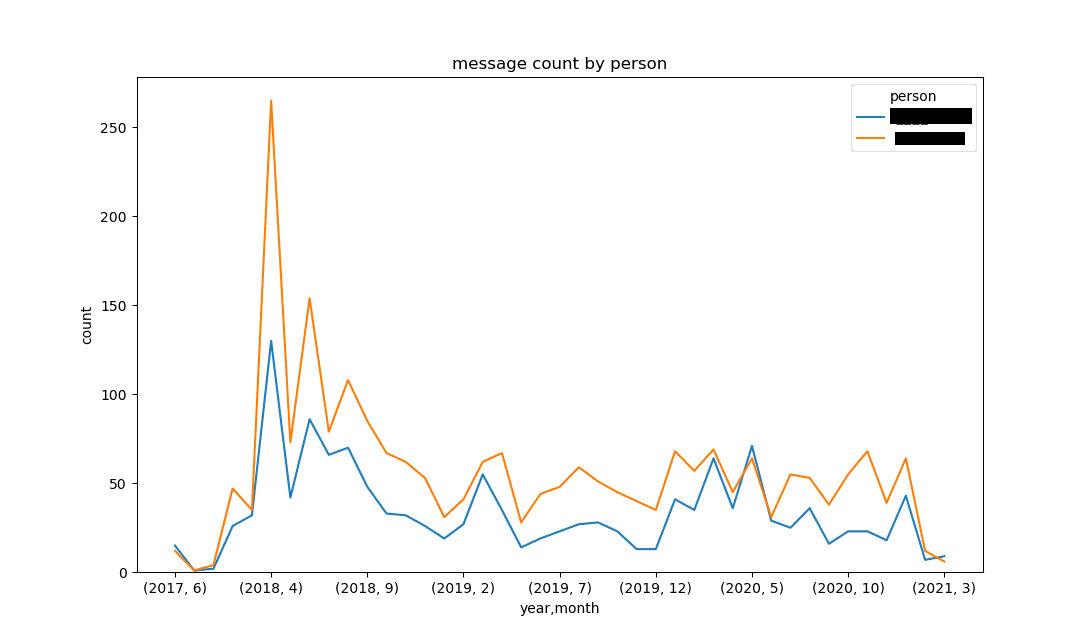
人ごとの月別メッセージ数
pandasでは、クロスタブを利用することで、簡単にクロス集計分析を行うことができます
1person_month_message = pd.crosstab([df['year'], df["month"]], df['person'])
2person_month_message.plot(kind='line', figsize=figsize)
3plt.title("message count by person")
4plt.ylabel("count")
5plt.ylim(0,)
6plt.savefig('message_count_by_person.png')
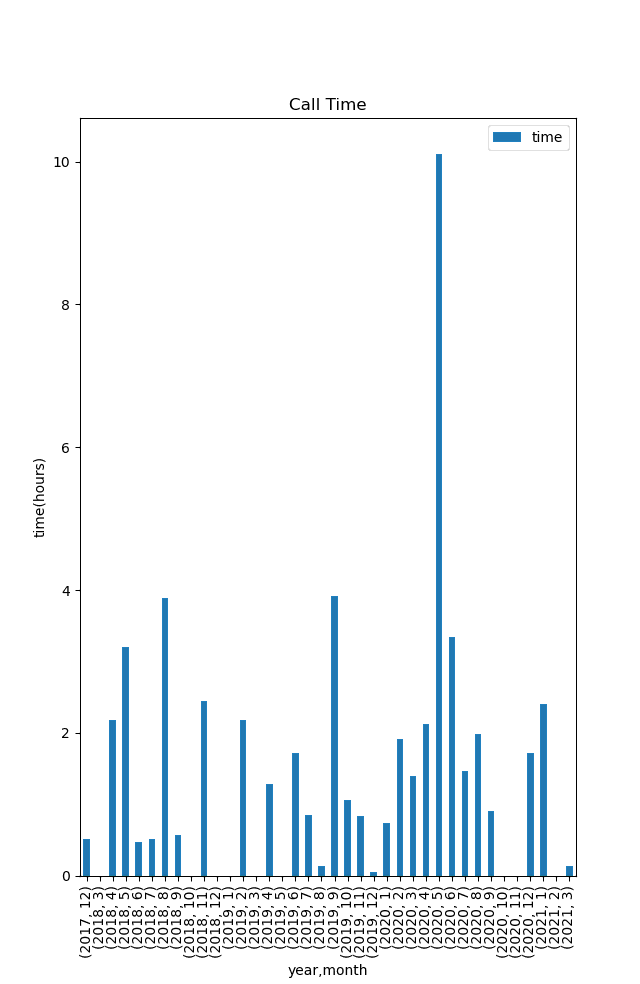
月別電話時間
電話のflagは10なのでまずは、csvからそのデータを取り出します。さらに電話時間はCSVに秒で記録されておりそのままでは、値が大きく理解しずらいため、3600でわり、時間にしました。
1call_time = df[df['flag'] == 10]
2call_time = call_time[["year", "month", "payloads"]]
3call_time = call_time.astype('int64').groupby(['year', 'month']).sum() / 3600
4call_time.plot(y='payloads', kind='bar', label='time', figsize=figsize)
5plt.ylabel("time(hours)")
6plt.legend()
7plt.ylim(0,)
8plt.title('Call Time')
9plt.savefig('call_time.png')
月別メッセージの文字数の合計
charというcolumnを作成し、そこにメッセージの文字数を入れたあとメッセージ数を数えた時と同じように、集計を行いました。
1# メッセージを取り出す
2char_count_data = df[df['flag'] == 0]
3# charというcolumnを作成し、そこにメッセージの文字数を入れる
4char_count_data["char"] = char_count_data["payloads"].apply(lambda x: len(x))
5char_count = char_count_data[["year", "month", "char"]]
6char_count = char_count.astype('int64').groupby(['year', 'month']).sum()
7char_count.plot(y='char', kind='bar', label='char', figsize=figsize)
8plt.ylabel("char")
9plt.legend()
10plt.ylim(0,)
11plt.title('char data')
12plt.savefig('char_count.png')

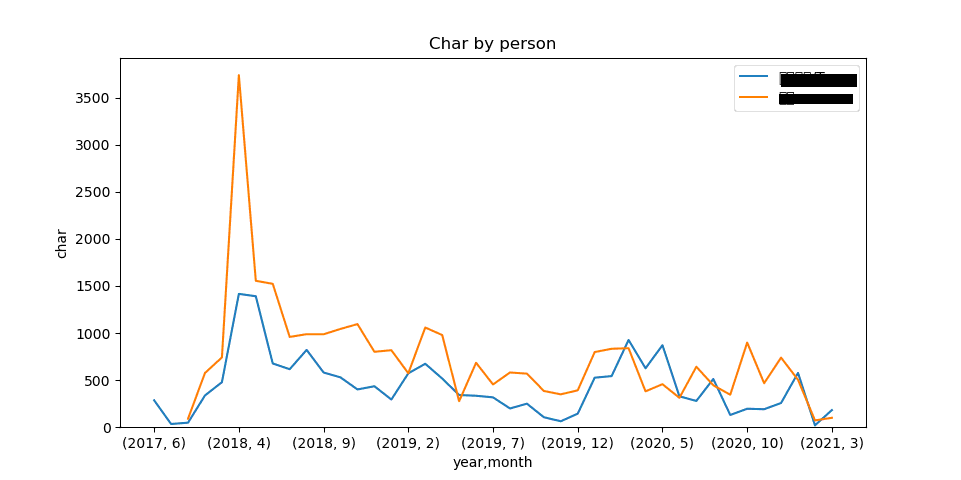
人べつ月ごとの文字数の合計
月別メッセージの文字数の合計で作成したデータフレームを再利用し人べつのデータを作成します。
1char_count_by_person = char_count_data[["year", "month", "person", "char"]]
2char_count_by_person["char"].astype('int64')
3char_count_by_person = pd.pivot_table(
4 char_count_by_person,
5 values="char",
6 index=["year", "month"],
7 columns="person",
8 aggfunc="sum"
9)
10char_count_by_person.plot(kind='line', figsize=figsize)
11plt.ylabel("char")
12plt.title('Char by person')
13plt.ylim(0,)
14plt.legend()
15plt.savefig('char_count_by_person.png')
解析するコードの全体
1# -*- coding: utf-8 -*-
2
3import pandas as pd
4import matplotlib.pyplot as plt
5
6file_path = "line.csv"
7
8figsize = (12, 8)
9df = pd.read_csv(file_path, names=('year', 'month', 'day',
10 'hour', 'minute', 'person', 'payloads', 'flag'), encoding="UTF-8")
11month_message = df[["year", "month", "flag"]
12 ].groupby(['year', 'month']).count()
13
14month_message.plot(y='flag', kind='bar', label="count", figsize=figsize)
15plt.ylabel("message count")
16plt.legend()
17plt.ylim(0,)
18plt.title('message')
19plt.savefig('message_count.png')
20
21person_month_message = pd.crosstab([df['year'], df["month"]], df['person'])
22person_month_message.plot(kind='line', figsize=figsize)
23plt.title("message count by person")
24plt.ylabel("count")
25plt.ylim(0,)
26plt.savefig('message_count_by_person.png')
27
28call_time = df[df['flag'] == 10]
29call_time = call_time[["year", "month", "payloads"]]
30newdf = pd.DataFrame([[2018, 3, 0], [2018, 10, 0], [2018, 12, 0], [2019, 1, 0], [2019, 3, 0], [2019, 5, 0], [2020, 10, 0], [2020, 11, 0], [2021, 2, 0], ],
31 columns=["year", "month", "payloads"])
32call_time.append(newdf, ignore_index=True)
33call_time = call_time.append(newdf)
34call_time = call_time.astype('int64').groupby(['year', 'month']).sum() / 3600
35call_time.plot(y='payloads', kind='bar', label='time', figsize=figsize)
36plt.ylabel("time(hours)")
37plt.legend()
38plt.ylim(0,)
39plt.title('Call Time')
40plt.savefig('call_time.png')
41
42char_count_data = df[df['flag'] == 0]
43char_count_data["char"] = char_count_data["payloads"].apply(lambda x: len(x))
44char_count = char_count_data[["year", "month", "char"]]
45char_count = char_count.astype('int64').groupby(['year', 'month']).sum()
46char_count.plot(y='char', kind='bar', label='char', figsize=figsize)
47plt.ylabel("char")
48plt.legend()
49plt.ylim(0,)
50plt.title('char data')
51plt.savefig('char_count.png')
52
53char_count_by_person = char_count_data[["year", "month", "person", "char"]]
54char_count_by_person["char"].astype('int64')
55char_count_by_person = pd.pivot_table(
56 char_count_by_person,
57 values="char",
58 index=["year", "month"],
59 columns="person",
60 aggfunc="sum"
61)
62char_count_by_person.plot(kind='line', figsize=figsize)
63plt.ylabel("char")
64plt.title('Char by person')
65plt.ylim(0,)
66plt.legend()
67plt.savefig('char_count_by_person.png')
以上でグラフを作成することができました。一度作ってしまえば実行するだけなので、定期的に実行して変化を試したいと思います。
Reference
以下のページを参考にしました